
Conținutul duplicat este o temă destul de controversată în lumea SEO; în vreme ce oficialii Google declară că nu ar trebui să ne facem griji în privința acestui aspect întrucât motorul de căutare se descurcă și singur să clasifice paginile web, majoritatea SEO-iștilor au un atac de panică atunci când în cadrul procesului de auditare descoperă pagini pline de conținut duplicat. Așa că haideți să aflăm împreună ce este conținutul duplicat, cum afectează ranking-ul în Google, care sunt cauzele, cum poate fi îndepărtat și care sunt măsurile preventive.

{kind=link}
Ce este conținutul duplicat?
Atunci când același conținut, fie că vorbim de un articol sau de un produs, poate fi accesat la adrese URL diferite avem de-a face cu conținut duplicat. De exemplu, în cazul în care conținutul de pe pagina https://www.admarks.ro/seo/ se găsește și pe pagina https://www.admarks.ro/seo.html, avem două pagini cu același conținut, adică conținut duplicat.
Tot conținut duplicat avem și atunci când cineva copiază conținutul de pe site-ul nostru pe un alt site.
Cum afectează conținutul duplicat ranking-ul în Google?
Conținutul duplicat nu este deloc un aspect de neglijat pentru că îngreunează foarte mult procesul de indexare al unui site. Atunci când pentru același conținut avem mai multe adrese URL, Google devine confuz și nu știe ce pagini să indexeze, moment în care se pot întâmpla următoarele:
- Google nu indexează niciuna dintre aceste pagini

Atunci când boții Google crawlează un site, se alocă anumite resurse în acest sens, resurse care sunt limitate (crawling budget). Mai pe înțelesul tuturor, Google nu explorează un site la nesfârșit, mai ales dacă detectează foarte multe pagini cu conținut nerelevant, precum paginile duplicat, moment în care limitează numărul de pagini care va fi indexat.
- Google indexează toate paginile
În cazul site-urilor mici (până în 10k pagini), se poate întâmpla ca Google să indexeze toate paginile pe care le întâlnește, indiferent că acestea sunt duplicat. Astfel, mai multe pagini din cadrul unui singur site vor concura între ele pentru aceleași cuvinte cheie, proces cunoscut și sub denumirea de canibalizarea landing page-urilor.
- Google indexează doar paginile greșite
Aceasta este cea mai frustrantă variantă. Practic, există și posibilitatea ca pagina principală, către care construim backlink-uri și cu care intenționăm să creștem în Google, să nu fie indexată, motorul de căutare alegând să indexeze în schimb celelalte pagini duplicat.
- Google indexează doar pagina care trebuie
În cel mai fericit caz, Google va realiza de unul singur care pagină trebuie indexată și le va ignora pe restul. Din păcate însă astfel de cazuri sunt destul de rar întâlnite, fiind aproape utopice.
Cauzele conținutului duplicat
Am lămurit că nu este bine să avem conținut duplicat și am aflat cum tratează Google această problemă, acum este timpul să stabilim care sunt cauzele conținutului duplicat și să descoperim cum și din ce cauză apare acesta.
- “www” vs „non-www”

{kind=link}
Un site poate funcționa atât în forma “www” (exemplu: www.domeniu.ro), cat si in forma “non-www” (domeniu.ro). Pentru ca Google să nu indexeze ambele variante, este necesar să se seteze o versiune preferată a site-ului. De exemplu, putem seta www.domeniu.ro ca variantă preferată, iar varianta domeniu.ro va fi redirecționată 301 către aceasta.
- „http” vs „https”

În cazul în care site-ul utilizează un certificat SSL, URL-urile acestuia nu vor mai fi de forma “http”, ci vor conține și litera „s” (secured), adică vor fi de forma “https” (exemplu: https://www.domeniu.ro). Din acest motiv, atunci când se instalează certificatul SSL, este necesar să se efectueze mai multe proceduri precum redirecționarea URL-urilor „http”, actualizarea sitemap-urilor, setarea URL-urilor peferate din conturile de Google Analytics și Google Search Console etc, pentru a asigura o migrare fără pierderi de ranking.
- Pagini tag
Până acum câțiva ani paginile tag erau extrem de des folosite, mai ales în cazul blogurilor, întâmplându-se ca un articol să aibă și câteva zeci de tag-uri. Folosite în mod excesiv, paginile tag pot dăuna foarte mult site-ului, întrucât pentru fiecare tag în parte se creează o pagină ce va conține articolele asociate acelui tag. Astfel, dacă se adauga tag-uri identice cu categoriile din site, vom avea același conținut atât pentru pagina tag, cât și pentru pagina de categorie.
- Versiunea de mobil
Unele site-uri care au o versiune dedicată terminalelor mobile, au in structura URL-urilor litera “m” (exemple:m.domeniu.ro sau domeniu.ro/m). Astfel, avem pentru fiecare pagină două adrese URL diferite (cea de mobil și cea de desktop).
Pentru a rezolva această problemă este nevoie ca URL-urile de mobil să conțină un tag canonical către URL-ul corespondent variantei desktop. De asemenea, URL-ul variantei desktop va conține tag-ul rel=alternate, cu trimitere către pagina corespondentă a variantei de mobil.
- Produse care aparțin mai multor categorii
O problemă des întâlnită în cazul magazinelor online este cea legată de duplicarea paginilor de produs. Se întâmplă mai ales atunci când paginile de produs păstrează în structura URL-urilor categoria/subcategoria din care fac parte (ex: domeniu.ro/categorie/subcategorie/produs) și același produs este adaugat în mai multe categorii/subcategorii. Astfel, dacă produsul „abc” este adăugat atât în categoria A, cât și în categoria B, vom avea pentru același produs două URL-uri (domeniu.ro/categoria-a/produs-abc/ și domeniu.ro/categoria-b/produs-abc/).
- Pagini de categorie duplicate prin indexarea filtrelor de sortare
Tot în cazul site-urilor de ecommerce, se întâmplă ca atunci când utilizatorul sortează produsele în funcție de preț, vânzări etc, la sfârșitul URL-ului să se genereze automat un parametru specific care duplică pagina principală de categorie.
- Conținut duplicat pentru homepage
Multe platforme generează în mod automat pagini de tipul domeniu.ro/index.html sau domeniu.ro/prima-pagina pentru homepage. Mai grav este atunci când aceste pagini se găsesc și în navigația site-ului (breadcrumbs, butonul de home, logo etc) și acumulează backlink-uri.
- Scrapers & plagiatori
Atunci când același conținut se găsește pe două sau mai multe site-uri vorbim despre conținut duplicat extern. Multe magazine online se lovesc de această problemă pentru paginile de produs deoarece de multe ori preferă să importe descrierea producătorului, decât să creeze conținut original pentru fiecare produs în parte.

Totodată, din păcate, și plagiatul este foarte întâlnit în mediul online, uneori întâmplându-se ca cei care plagiază să rankeze peste site-urile de unde au copiat conținutul.
Cum identificăm conținutul duplicat
Identificarea conținutului duplicat nu este o operațiune chiar atât de facilă pe cât pare la prima vedere și de multe ori este nevoie de ore întregi de research pentru a identifica diferite tipare de URL-uri duplicat. Din fericire, există tool-uri pe care le putem folosi pentru a ne automatiza munca.
- Google Search Console
Instrumentul Google Search Console se poate dovedi extrem de util în identificarea conținutului duplicat. Pentru aceasta, este nevoie să accesăm meniurile „Search Appearance” – „HTML Improvements”. În cazul în care sunt raportate meta descrieri sau meta titluri duplicat, este necesar să descărcăm listele și să le studiem pentru a putea stabili cauzele.

- Screaming Frog
Screaming Frog este un tool esențial în identificarea problemelor de indexare și ne poate ajuta și în privința conținutului duplicat. Acest tool analizează toate paginile unui site și ne oferă informații despre structura site-ului, tag-urile meta, status code, hreflang, tipul fișierelor din site etc.
Pentru a găsi conținutul duplicat cu ajutorul Screaming Frog, trebuie să sortăm URL-urile în funcție de atributele „meta title”, „meta description” sau „H1”.

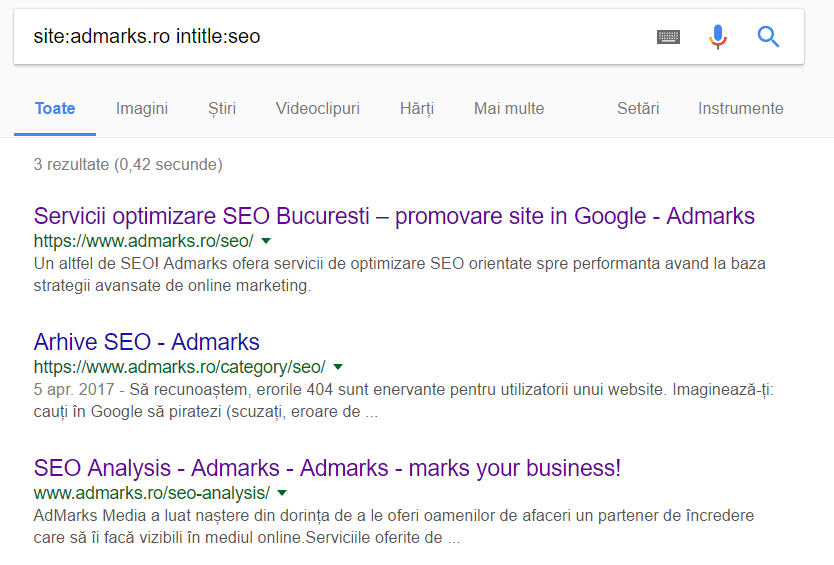
- Comanda „site:”
Nu toate URL-urile identificate de tool-ul Screaming Frog sunt si indexate in Google. Pentru a găsi URL-urile duplicat indexate, se pot folosi comenzile “site:domeniu.ro inurl:cuvant cheie” sau „site:domeniu.ro intitle:cuvant cheie” atunci când căutam în Google.
Spre exemplu, dacă în urma analizei cu Screaming Frog observăm că pentru paginile de categorie se generează, prin intermediul sistemului de filtrare, parametrul „sort=?” în URL, putem verifica apoi dacă și câte din aceste URL-uri au fost indexate folosind în Google comanda „site:domeniu.ro inurl:sort=?”
- Siteliner
Siteliner ne poate ajuta să identificăm blocurile de text identice prezente în pagini diferite ale site-ului nostru, afișând și procentul conținutului unic pentru fiecare pagină în parte. De asemenea, acest tool ne poate furniza și informații relevante despre calitatea conținutului nostru.

- Copyscape
Copyscape este unul dintre cele mai utilizate tool-uri pentru a detecta conținutul plagiat, fiind extrem de eficient în identificarea site-urilor care ne copiază conținutul.
Cum rezolvăm problema conținutului duplicat
După identificarea conținutului duplicat, este nevoie să-l eliminăm, iar pentru aceasta avem la dispoziție următoarele variante:
- Canonicalizare pagini
Cea mai la îndemână metodă de a scăpa de conținutul duplicat este folosirea atributului rel=”canonical”. Acest atribut are rolul de a informa motoarele de căutare ce pagină să indexeze.
Spre exemplu, dacă în locul paginii “domeniu.ro/produs-sort=?” vrem sa se indexeze pagina „domeniu.ro/produs”, este nevoie să definim următorul tag canonical în secțiunea <head> a codului HTML:
<link rel=”canonical” href=”domeniu.ro/produs” />

{kind=link}
- Redirect 301
În cazul în care paginile duplicat nu prezintă interes pentru utilizatori, acestea pot fi redirecționate 301 către paginile principale, această metodă fiind și cea mai rapidă. Atenție însă la numărul redirecționărilor fiindcă pot mări viteza de încărcare a site-ului.
- Blocarea conținutului via robots.txt
Robots.txt este un fișier ce are rolul de a informa motoarele de căutare despre paginile pe care să nu le indexeze. Acest instrument este foarte util atunci când se dorește blocarea de la indexare a URL-urilor ce conțin anumiți parametri.
De exemplu, pentru a bloca de la indexare toate URL-urile ce conțin parametrul “sort=?” este nevoie să adăugăm următoarea linie de cod în fișierul robots.txt:
Disallow: /*sort=?
- Meta robots noindex
Un alt meta tag foarte folositor în lupta împotriva conținutului duplicat este “meta robots”. Prin definirea atributului content=”noindex” in secțiunea head a paginii respective, informăm motoarele de căutare să nu indexeze pagina respectivă. <meta name=”robots” content=”noindex,follow”>
- Setarea domeniului preferat în GSC
Pentru a fi siguri că site-ul nostru nu este indexat atât în forma www, cât și non-www, este necesar să setăm domeniul preferat via Google Search Console.
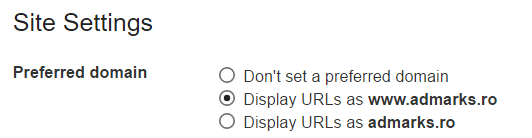
De exemplu, dacă dorim să se afișeze URL-urile în forma www, vom folosi secțiunea “Site Settings” din GSC și vom bifa căsuța “Display URLs as www.domeniu.ro”.
- Folosirea de clean URLs
O metodă elegantă de a rezolva problema paginilor duplicat de produs din mai multe categorii este folosirea de clean URLs, adică URL-uri ce se formează direct din root.
Astfel în cazul unei pagini de produs, URL-ul va fi „domeniu.ro/produs”, în loc de „domeniu.ro/categorie/subcategorie/produs”. În acest mod, vom putea introduce același produs în mai multe categorii fără a mai avea conținut duplicat.
Cum să prevenim apariția conținutului duplicat
Cea mai bună metodă de a rezolva problema conținutului duplicat este de a împiedica apariția acestuia prin luarea unor măsuri de precauție.
- Self canonical
Prin self canonical înțelegem că o pagină are implementat atributul „rel=canonical” către ea însăși. Prin această metodă se va împiedica indexarea de pagini duplicat precum cele generate de sistemul de filtrare, întrucât aceste pagini generate dinamic vor avea în mod automat canonical către pagina principală.
- Verificări periodice
Conținutul duplicat trebuie identificat din timp, pentru a nu permite subminarea si canibalizarea paginilor principale. Din acest motiv este recomandat să se efectueze verificări periodice cu Screaming Frog, prin intermediul comenzii de căutare „site:” sau via Search Console.